《30天到3分钟的改变!》系列主要讨论机器学习流程的三个阶段:数据获取和处理、模型训练和评估、模型部署和迭代。在第一期中我们通过数据接入能力、数据准备能力、数据探索和可视化能力三部分,介绍了机器学习建模流程和机器学习平台在数据获取和处理方面需要具备的能力,以及DataCanvasAPS相关的功能特性。本期将重点讨论模型训练和评估!
模型训练和评估
Gartner将数据科学家分成两类:
●ExpertDataScientist(核心数据科学家)
核心数据科学家就是传说中的具备各种交叉学科的综合能力,有深厚的统计学、数学功底,有丰富的数据挖掘、机器学习的经验,有较强的编码能力,对某些业务领域有深入理解的专家。在今天,这样的大神也是凤毛麟角,随着对AI需求的爆发,全部依赖核心数据科学家完成建模工作只能是一个奢侈的愿望,因此衍生出了平民数据科学家的概念。
●CitizenDataScientist(平民数据科学家)
平民数据科学家的门槛更低,他们具备一些统计分析的背景,具有一定建模工具的使用经验,对某个业务领域有较深的理解。平民数据科学家可以很好的弥合企业的建模需求与核心数据科学家严重不足之间的鸿沟,但是真正填补这个鸿沟的实质因素是机器学习平台在建模工具和自动化技术上的突破。
编码、拖拽、自动化三位一体的建模工具已经是机器学习平台必备的能力。核心数据科学家通常更倾向使用IDE、Notebook通过编码的方式完成建模。平民数据科学家更多的是通过拖拽式的可视化建模,甚至是通过AutoML自动建模工具完成建模。当然AutoML同样可以帮助核心数据科学家减少重复劳动,比如自动特征衍生、自动超参数优化、自动模型筛选等。另外拖拽式建模中的模块封装也是通过模块化的思想实现代码沉淀、复用,以及模型生产化和迭代中不可或缺的工程化支撑。
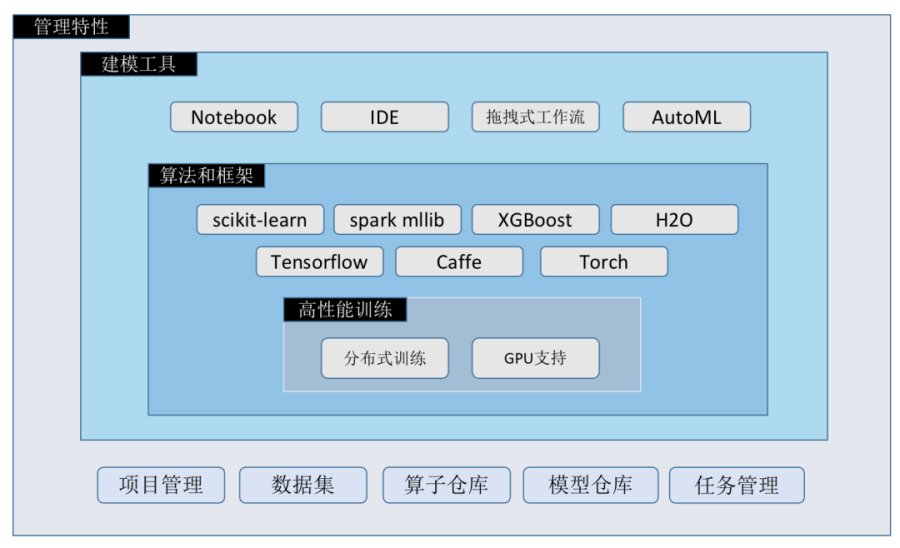
机器学习平台示意图
建模工具是数据科学家的入口,如上图:在建模工具下层是算法和框架的支持,再深入是高性能训练、资源调度的支持,在建模工具之上还需要很多管理特性的支撑,这四个方面是支撑机器学习模型训练和评估的基础。
接下来我们就展开介绍一下:
1、建模工具
使用Notebook交互式编码工具是目前非常流行的建模方式,比较常用的有JupyterNotebook、JupyterLab,以下简称notebook和lab。
notebook的特色是可以实现代码片段(cell)的运行调试不需要每次都运行全部代码,代码段的运行结果(图表、数据、文本)直接显示在代码下方,我们还可以使用markdown插入富文本的说明增加整个notebook的可读性。notebook完成之后,我们还可以选择隐藏掉所有的代码cell只保留文档和运行结果生成一个图文并茂的报告,并且可以导出成html、pdf等格式的文档,这些功能在传统的IDE中都是无法实现的,也是数据科学家们钟爱它的原因。lab可以理解为是一个可以同时打开多个notebook的IDE工作台,功能更加强大。
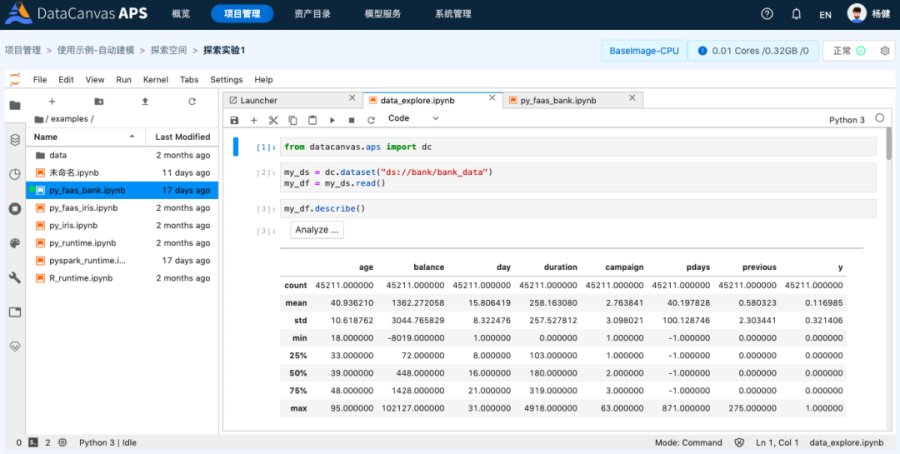
APS在探索空间集成的JupyterLab
APS在分析模块中集成的JupyterNotebook
APS分析模块中的IDE
拖拽式建模基本上可以算是机器学习平台的标配,其主要原因是:
1、门槛低,不需要编程;
2、可视化,工作流可以让建模过程一目了然;
3、模块化,工作流上的每一个节点完成特定的工作,好的平台不但提供足够多的预置模块还可以让用户自己开发模块实现代码积累和复用。
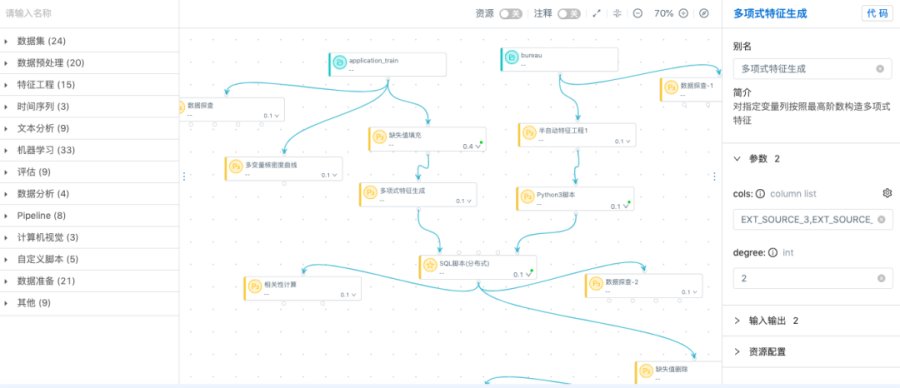
APS的工作流开发界面
AutoML是近几年机器学习领域的热点,Gartner预计到2020年40%的建模工作是通过自动化方式完成的。全流程的自动化是一个终极目标,从自动准备宽表、特征衍生和加工、模型选择、超参数优化、模型融合到自动化的模型迭代。在深度学习领域NAS(神经网络架构搜索)和强化学习、迁移学习可以大幅提升建模效率、减少对核心数据科学家的依赖。
从本质上说自动建模是一个用算力换算法的过程,那么如何使用更少的算力得到更优质的算法模型是考验AutoML水平的核心问题,其中包括元学习的方法、贝叶斯优化算法、基于Boosting思想的特征选择方法等等,在学界和业界呈现百花齐放的状态。在此之上人类经验目前还是提升模型性能的关键要素,如何把人类经验和AutoML能力有机结合,APS给出了自己的方案:
APS提供了面向结构化数据的通用建模工具,可以满足一般性的回归和分类问题。同时APS提供了一个AutoML开发框架,通过这个开发框架,我们可以把核心数据科学家在建模过程中积累的经验转化成AutoML的一部分规则,最后生成一个面向细粒度业务场景的自动化建模插件。比如:自动时序数据的异常检测、自动评分卡建模、自动文本分类、图像分类等等。业务人员只要按要求准备好数据就可以完成一键建模。目前APS内置的所有自动建模插件都是基于这个开发框架完成。
2、算法和框架
对于算法和各种框架的支持是模型训练的最基本能力,但也是考验平台开放性的一个重要方面。很多商业化平台向用户提供了非常丰富的商业闭源算法如SAS、RapidMiner,他们在平台内预置了大量的数据挖掘和传统机器学习算法,但单一厂商在算法上的进步是无法比拟和对抗整个开源生态的发展的。虽然这些厂商也逐渐在向开源阵营靠拢,但原生架构上的闭源思路会成为平台开放性的羁绊。
2019年3月tensorflow2.0alpha发布,到6月发布了2.0beta版,在Github上获得了超过13万星,被fork76000次以上,在整个技术圈的热度近年只有996.ICU能与之匹敌。
ONNX(开放神经网络交换)开源项目更是打通了深度学习框架甚至是传统机器学习框架之间的壁垒,模型可以在不同的机器学习框架之间互通、转换。用PyTorch训练的模型可以使用Tensorflow来做推理Serving,这大大提升了学术研究向工业应用的转化速度。
2018年BERT的开源以其优异的表现震撼了整个NLP界,甚至砸碎了很多NLP企业赖以生存的饭碗。就在BERT风头正劲时XLnet又席卷而来,20项任务全面碾压BERT。是的,这就是开源。
不夸张的说,一个平台是否能分享开源生态的快速发展所带来的技术红利已经成为影响企业在AI战略上能否抢占先机的核心要素。
APS自下而上的开放性架构使开源和商业化产品完美结合。APS预置了常用的机器学习框架scikit-learn、sparkml、tensorflow、keras等,同时基于以上框架封装了大量的预置模块供用户直接使用。在此基础上,用户可以自行扩展来支持更多的框架和算法:
●通过环境管理可以实现运行时环境和算法框架的安装来完成运行环境的准备;
●通过探索空间结合构建好的运行环境可以使用任意算法框架来完成模型的探索和训练;
●通过分析模块可以把算法封装成可以复用的模块,在工作流中通过拖拽式完成模型训练和模型迭代。
3、高性能训练
人工智能时代几乎是伴随着大数据时代同时爆发,这并非偶然,其必然性的内因是数据量级和计算能力的飞跃,这是今天机器学习建模真正能够产生突破性进展的根本原因。不管是传统统计机器学习还是深度学习,足够大的数据量是模型表现的第一要素,因此能够调度计算资源在最短的时间内完成大数据量的模型训练是机器学习平台的一个关键能力。目前主要围绕着以下两个方面实现高性能模型训练:并行分布式计算、GPU支持。
并行计算的伸缩模式有两种:
1、scaleup(纵向伸缩、单机多处理器模式)
2、scaleout(横向伸缩、多机多处理器模式)
我们知道纵向伸缩模式是把单台物理机的硬件配置向上升级(比如处理器从1个升级到4个,内存从64G升级到1T),但是一旦物理机的资源超过一定的临界值之后向上升级的成本会陡然增加而且最终会到达极限,成本和性能之间将不在保持线性关系(PCServer->小型机->Mainframe大型机->超级计算机)。这也就是分布式架构产生的背景,我们需要一个可以横向伸缩的架构,通过增加更多的物理机来提升整体系统的处理能力。两种模式相比,在能处理相同数据量的情况下纵向升级的ROI(投入产出比)要远远高于横向升级,1台机器同时使用4个CPU一定比同时使用4台机器每台1个CPU的性能要高。但是一旦突破了单个物理机升级的极限,我们就只有一个选择就是利用分布式系统横向伸缩来满足更大数据量级的需求。
目前并行分布式计算的范式主要有几种:MPI、MapReduce、BSP,我们常见的Hadoop、Spark都是MapReduce范式,基于Spark的分布式机器学习框架是目前传统统计机器学习模型训练的主流。其实使用Spark做机器学习也存在一定的缺陷:
1、Spark是面向大数据场景的分布式计算引擎,其计算模型主要是针对二维数据的关系代数计算(筛选、连接、聚合等),但是机器学习中以科学计算为主,比如:多维数组和张量的计算、矩阵运算、快速傅立叶变换等。虽然Spark引入了Breeze线性代数工具包支持科学计算,但其原生架构上的设计决定了在机器学习场景中的计算效率和开发接口的友好性上都难以令人满意。
2、对于数据科学家来说更加熟悉Python的数据科学生态和工具,强迫数据科学家使用Spark(即使是PySpark)确实面临一些学习成本和障碍。近几年开源社区贡献了几个非常出色的分布式科学计算引擎,如:Dask、Mars(阿里开源)、modlin等。尤其是Dask能够兼容numpy、pandas、scikit-learn现有的大部分api接口,只要极少的代码改造,就可以实现分布式大数据量的处理和模型训练。
在深度学习领域比较常见的是基于PS架构(参数服务器)的分布式训练,Tensorflow原生提供的就是这种模式。同时也有采用AllReduce的MPI架构,比如Uber开源的Horovod就是基于Ring-AllReduce的MPI架构来实现Tensorflow、Caffe、PyTorch等框架的分布式训练。AllReduce的性能和GPU利用率表现更好,而且并行度越高效果越明显,据统计同时使用128块GPU卡的分布式训练任务中Horovod比Tensorflow原生的性能高2倍左右,在GPU价格极其昂贵的今天,这无异于节省一半的成本投入。
APS支持了非常丰富的并行计算模式,包括:
●单机多处理器模式,用于支持多CPU的机器学习算法的并行训练,如XGBoost、Scikit-Learn中支持n_jobs参数的算法等;
●基于Spark的分布式计算引擎,用PySpark实现大规模数据处理和SparkML中提供的机器学习算法训练;
●基于Dask的分布式计算引擎,用Python完成大数据量的数据处理和机器学习模型训练(目前仅在探索空间中提供实验性支持);
●基于MPI架构AllReduce的分布式深度学习训练,用于完成Tensorflow基于GPU的分布式训练。
4、管理特性
在选择机器学习平台时经常被忽视的就是管理特性,以往我们的数据科学家都是使用本地电脑或者一台服务器来完成全部的建模过程,这种方式在模型初期验证和实验阶段还可以,一旦进入生产化阶段没有很好的管理功能支撑往往会陷入困境(在我前面的故事篇中有一些相关描述)。在企业中通常会组建由业务专家、数据科学家、数据工程师、算法工程师、开发工程师共同组成的项目组来完成建模任务,机器学习平台要能够满足团队协同工作的需求。APS提供了用户管理、项目管理、权限分配、代码和工作流的版本管理、模型管理等一系列功能,管理特性是APS非常重要的部分而且涵盖相当丰富的内容,我后面会专门写一篇APS有关管理方面的专题来详述。
下期预告:
《30天到3分钟的改变!》下篇——模型部署和迭代
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
-
 每日热点:“祝融号”又有新发现!我国科学家研究证明火星北部曾存在海洋近日,中国地质大学(武汉)地球科学学院肖龙教授领导的国际研究团队,通过综合分析“祝融号”火星车搭载的多光谱相机(MSCam)获...
每日热点:“祝融号”又有新发现!我国科学家研究证明火星北部曾存在海洋近日,中国地质大学(武汉)地球科学学院肖龙教授领导的国际研究团队,通过综合分析“祝融号”火星车搭载的多光谱相机(MSCam)获... -
 观察:2023年5月吉林证券从业资格预约式报名时间:5月12日-18日考生可登录中国证券业协会进行报名!1 报名时间证券从业高频考点、免费课件等,免费领取中>>>(资料图)吉林2023年5月证券从业...
观察:2023年5月吉林证券从业资格预约式报名时间:5月12日-18日考生可登录中国证券业协会进行报名!1 报名时间证券从业高频考点、免费课件等,免费领取中>>>(资料图)吉林2023年5月证券从业... -
 亳州市职业教育 活动周启动|微头条(资料图)5月17日,2023年亳州市职业教育活动周启动仪式在市区魏武广场举行。启动仪式指出,要高度重视职业教育发展,大力发展...
亳州市职业教育 活动周启动|微头条(资料图)5月17日,2023年亳州市职业教育活动周启动仪式在市区魏武广场举行。启动仪式指出,要高度重视职业教育发展,大力发展... -
 蛟河市人才工作会议暨“百优”人才通报表扬大会召开(资料图片)5月17日,蛟河市人才工作会议暨“百优”人才通报表扬大会在蛟河市工人文化宫召开。与会人员共同观看了人才宣传片,...
蛟河市人才工作会议暨“百优”人才通报表扬大会召开(资料图片)5月17日,蛟河市人才工作会议暨“百优”人才通报表扬大会在蛟河市工人文化宫召开。与会人员共同观看了人才宣传片,... -
 2023一级建造师《机电工程》每日测试题(05月18日)|天天关注(资料图)扫描二维码下载题库帮助一建考试学习参加每日一建考试打卡获取一建考试模拟试题获取历年一建真题试卷获取一建考试各...
2023一级建造师《机电工程》每日测试题(05月18日)|天天关注(资料图)扫描二维码下载题库帮助一建考试学习参加每日一建考试打卡获取一建考试模拟试题获取历年一建真题试卷获取一建考试各...




















-
每日热点:“祝融号”又有新发现!我国科学家研究证明火星北部曾存在海洋
2023-06-02 08:46:25
-
观察:2023年5月吉林证券从业资格预约式报名时间:5月12日-18日
2023-06-02 08:46:25
-
亳州市职业教育 活动周启动|微头条
2023-06-02 08:46:25
-
蛟河市人才工作会议暨“百优”人才通报表扬大会召开
2023-06-02 08:46:25
-
2023一级建造师《机电工程》每日测试题(05月18日)|天天关注
2023-06-02 08:46:25


